Discover why data preprocessing in machine learning is crucial for model accuracy. Learn key techniques, best practices, and real-world examples in this comprehensive guide.

Introduction: Why Data Preprocessing is the Backbone of ML Success
Did you know that 80% of a data scientist’s time is spent cleaning and preparing data? Without proper data preprocessing in machine learning, even the most advanced algorithms fail to deliver accurate results.
In this guide, we’ll break down the essential steps, techniques, and best practices to transform raw data into a goldmine for machine learning models. Whether you’re a beginner or an expert, mastering data preprocessing will drastically improve your model’s performance.
What is Data Preprocessing in Machine Learning?
Data preprocessing in machine learning is the process of cleaning, transforming, and structuring raw data into a format that algorithms can interpret efficiently. It ensures:
- Higher accuracy in predictions
- Faster training times
- Reduced bias and errors
Why is Data Preprocessing Necessary?
- Real-world data is messy (missing values, outliers, inconsistencies).
- ML models require structured input (numerical, normalized, encoded).
- Poor data quality leads to garbage-in-garbage-out (GIGO) results.
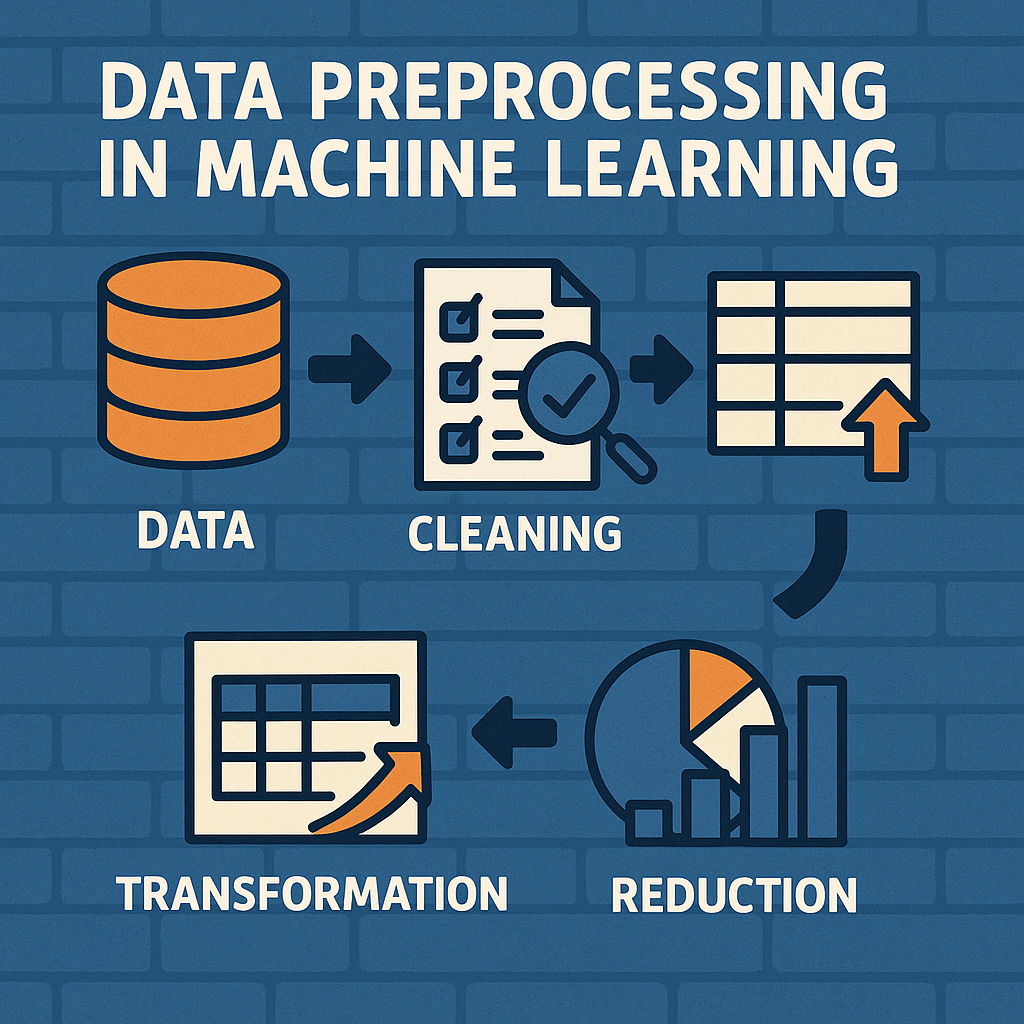
Key Steps in Data Preprocessing for Machine Learning
1. Data Cleaning – Handling Imperfections
- Missing Data: Use imputation (mean, median, mode) or deletion.
- Outliers: Apply IQR, Z-score, or clustering techniques.
- Noise Reduction: Smoothing or binning methods.
2. Data Transformation – Standardizing for Consistency
- Normalization (Min-Max Scaling): Rescales features to [0, 1].
- Standardization (Z-Score): Centers data around mean (μ=0, σ=1).
- Log/Box-Cox Transforms: For skewed data distributions.
3. Feature Encoding – Converting Categorical Data
- Label Encoding: Assigns integers to categories (e.g., “High” → 2).
- One-Hot Encoding: Creates binary columns for each category.
4. Feature Selection & Dimensionality Reduction
- Correlation Analysis: Remove redundant features.
- PCA (Principal Component Analysis): Reduces feature space.
Most Used Data Preprocessing Libraries
When working with data preprocessing in machine learning, these Python libraries are essential:
- Provides all core preprocessing tools:
SimpleImputer(missing values)StandardScaler,MinMaxScaler(feature scaling)OneHotEncoder,LabelEncoder(categorical encoding)PCA(dimensionality reduction)
- Essential for data manipulation:
fillna(),dropna()(missing data handling)get_dummies()(one-hot encoding)- Data filtering and transformation
- Foundation for numerical operations:
- Mathematical transformations
- Statistical operations for outlier detection
- Array operations for efficient data handling
- Specialized library with advanced preprocessing:
- Rare category encoding
- Arbitrary discretization
- String pattern extraction
- Scalable preprocessing for large datasets:
- Distributed data cleaning
- Parallel feature engineering
- Integration with MLlib
Pro Tip: Most data scientists use Scikit-learn + Pandas for 90% of preprocessing tasks, only reaching for specialized libraries when needed.
Real-World Case Study: How Preprocessing Improved Model Accuracy
A healthcare ML model predicting diabetes initially had 72% accuracy. After proper data preprocessing (handling missing values, scaling, and encoding), accuracy jumped to 89%!
Best Practices for Effective Data Preprocessing
- Automate repetitive tasks (using Scikit-learn pipelines).
- Always split data (train/test) before preprocessing to avoid leakage.
- Document every preprocessing step for reproducibility.
FAQ – Answering Common Data Preprocessing Questions
What are the most common data preprocessing techniques?
- Handling missing values (imputation/removal).
- Scaling & normalization (MinMax, StandardScaler).
- Encoding categorical variables (One-Hot, Label Encoding).
How does data preprocessing affect model performance?
Poor preprocessing leads to biased, slow, or inaccurate models. Proper preprocessing boosts accuracy, speed, and reliability.
Can I skip data preprocessing in ML?
No! Raw data is rarely ML-ready. Skipping preprocessing often leads to failed models.
Conclusion: Unlock Your ML Potential with Proper Data Preprocessing
Data preprocessing in machine learning isn’t just a step—it’s the foundation of successful AI models. By following best practices and leveraging powerful libraries like Scikit-learn and Pandas, you ensure your algorithms work with clean, optimized data for maximum accuracy and efficiency.
Ready to implement ML in your organization? Book a consultation with our experts.