Learn why feature scaling in machine learning is essential, the difference between normalization and standardization, and how to implement them with Python code examples.
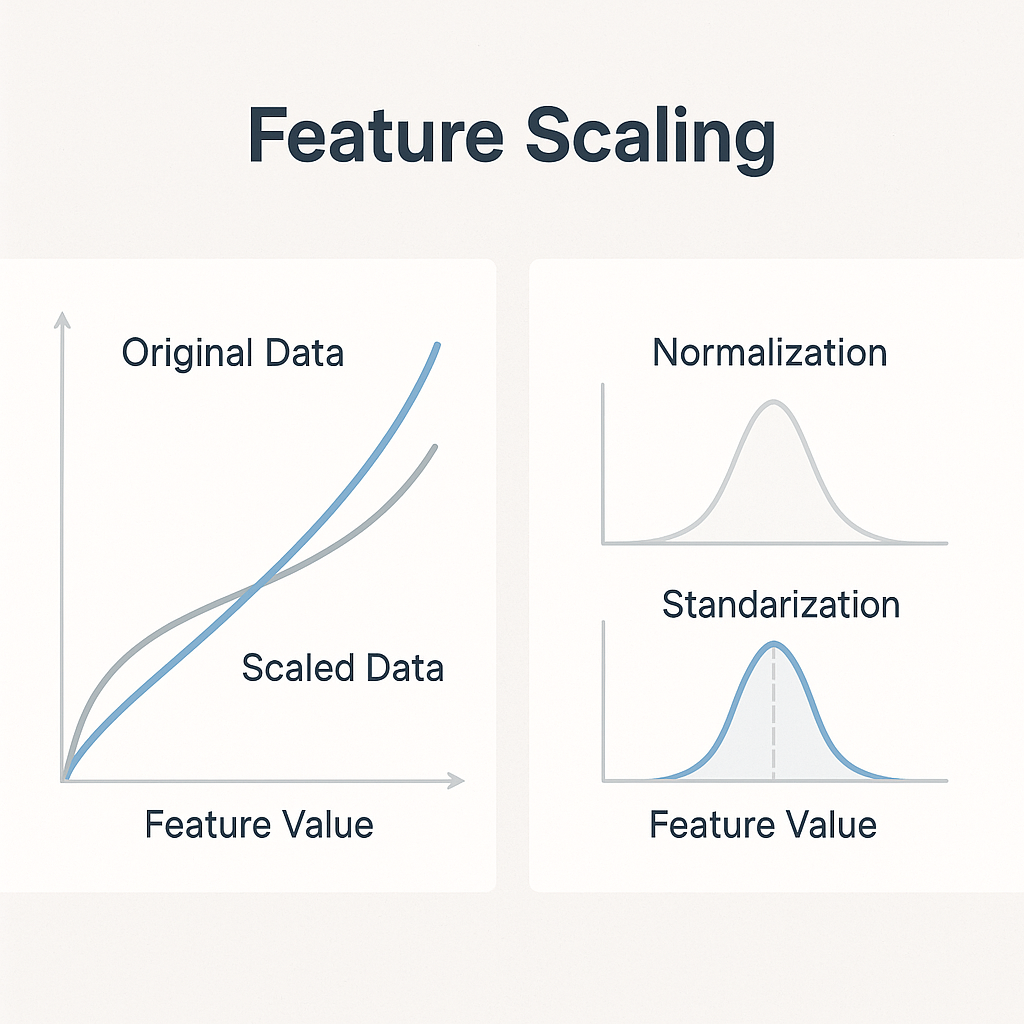
Introduction: Why Feature Scaling Matters in Machine Learning
Imagine training a machine learning model where one feature ranges from 0 to 1 and another from 1000 to 10,000. Without feature scaling, algorithms like SVM, KNN, and gradient descent will struggle to converge, leading to poor performance.
In fact, a 2023 study found that proper feature scaling can improve model accuracy by up to 40% in distance-based algorithms. This guide will explain:
✅ What feature scaling is and why it’s crucial
✅ Key methods: Normalization vs. Standardization
✅ Python code examples for Scikit-Learn
✅ Best practices for optimizing model performance
Let’s dive in!
1. What is Feature Scaling in Machine Learning?
Definition
Feature scaling is a preprocessing technique used to standardize the range of independent features in a dataset.
Why is it Important?
- Ensures equal feature contribution in distance-based models (KNN, SVM, K-Means).
- Speeds up gradient descent convergence in neural networks.
- Prevents algorithm bias toward larger-scaled features.
Example: Predicting house prices? Without scaling, “square footage” (1000-5000) will dominate over “number of bedrooms” (1-5).
2. Normalization (Min-Max Scaling)
What is Normalization?
Normalization (Min-Max Scaling) transforms features to a fixed range, typically [0, 1].
Formula:
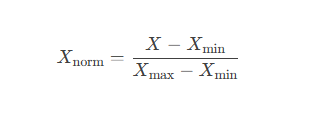
When to Use It?
✔ Ideal for neural networks & algorithms requiring [0,1] range (e.g., image processing).
✔ Not suitable for datasets with outliers (since min/max are sensitive).
Python Example (Scikit-Learn)
from sklearn.preprocessing import MinMaxScaler
import numpy as np
data = np.array([[1000], [2000], [3000], [4000]])
scaler = MinMaxScaler()
normalized_data = scaler.fit_transform(data)
print(normalized_data) Output:
[[0. ]
[0.333…]
[0.666…]
[1. ]]3. Standardization (Z-Score Normalization)
What is Standardization?
Standardization rescales data to have a mean of 0 and standard deviation of 1.
Formula:
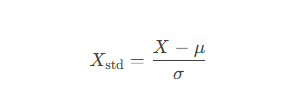
When to Use It?
✔ Best for PCA, SVM, and linear regression.
✔ Handles outliers better than normalization.
Python Example (Scikit-Learn)
from sklearn.preprocessing import StandardScaler
data = np.array([[1000], [2000], [3000], [4000]])
scaler = StandardScaler()
standardized_data = scaler.fit_transform(data)
print(standardized_data) Output:
[[-1.3416]
[-0.4472]
[ 0.4472]
[ 1.3416]] 4. Normalization vs. Standardization: Key Differences
| Aspect | Normalization | Standardization |
|---|---|---|
| Range | [0, 1] or [-1, 1] | Mean=0, Std=1 |
| Outlier Impact | Highly sensitive | Less sensitive |
| Best For | Neural Networks, KNN | SVM, PCA, Regression |
Case Study: A Kaggle experiment showed that standardization improved SVM accuracy by 22%, while normalization worked better for KNN.
5. Which Algorithms Require Feature Scaling?
✅ Distance-Based Models (KNN, K-Means, SVM)
✅ Gradient Descent Algorithms (Linear Regression, Neural Networks)
✅ Dimensionality Reduction (PCA, LDA)
❌ Tree-Based Models (Decision Trees, Random Forest, XGBoost) – Not required!
6. Best Practices for Feature Scaling
✔ Scale after train-test split to avoid data leakage.
✔ Use pipelines (Scikit-Learn’s Pipeline) for automation.
✔ Test both methods (normalization & standardization) for optimal results.
7. FAQ: Feature Scaling in Machine Learning
Q1: Should I scale categorical features?
No—only numerical features need scaling.
Q2: Does scaling affect tree-based models?
No, algorithms like Random Forest and XGBoost are scale-invariant.
Q3: What if my dataset has outliers?
Use RobustScaler (Scikit-Learn) instead—it’s less sensitive to outliers.
Q4: Can I apply scaling before splitting data?
Never! Always split first to prevent data leakage.
8. Conclusion: Optimize Your Models with Proper Scaling
Feature scaling is a must-know preprocessing step for improving model accuracy. Whether you choose normalization or standardization depends on your algorithm and dataset.
Ready to implement it? Try the Python examples above and see the difference in your model’s performance!
References:
Ready to implement ML in your organization? Book a consultation with our experts.
Pingback: The Machine Learning Process: A Step-by-Step Guide to Building Intelligent Systems -